
0819. Most Common Word (Easy)
(當然,Medium的拍手也可以多拍幾下啦XD)
Question
Given a paragraph and a list of banned words, return the most frequent word that is not in the list of banned words. It is guaranteed there is at least one word that isn’t banned, and that the answer is unique.
Words in the list of banned words are given in lowercase, and free of punctuation. Words in the paragraph are not case sensitive. The answer is in lowercase.
Example:
| |
Note:
1 <= paragraph.length <= 1000.0 <= banned.length <= 100.1 <= banned[i].length <= 10.- The answer is unique and written in lowercase (even if its occurrences in
paragraphmay have uppercase symbols, and even if it is a proper noun.) paragraphonly consists of letters, spaces, or the punctuation symbols!?',;.- There are no hyphens or hyphenated words.
- Words only consist of letters, never apostrophes or other punctuation symbols.
分析/解題
給定一個段落和一個被禁止的字的列表,回傳這個段落裡面出現次數最高且沒有在禁止字列表內的字。
(題目保證至少有一個字不會被禁止且答案只會有一個)
禁止字表會以小寫字給定且不需考慮標點符號,
在段落中的字並不限定大小寫(也就是視作相同的字),
答案要用小寫表示。
這題一般而言會使用HashMap或dict來解題,
但隨著總字數的增加,一些重複的字母不斷出現感覺其實相對浪費,
所以今天就要專門來介紹一個資料結構來解決這個問題,
這個資料結構就是字典樹(Trie)。
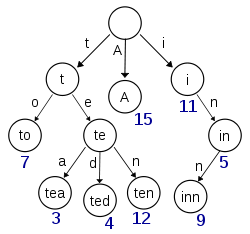
Trie (From Wikipedia)
字典樹長得基本上就是樹的一種,通常儲存的是字串。
其根節點代表著空字串 ,而每個連結出去的節點,
都代表在前面的基礎上加上一個字元(char) 。
換句話說,我們只要知道從根到葉走了哪些鏈結,
就知道最終葉所代表的字串是什麼,如上圖所示。
在這題當中,我們可以自行定義一個class TrieNode,
當中包含了links (從這個節點連出去26個字母),
cnt (這個字在整個段落出現的次數),以及word (實際上這個字是什麼)。
其實word可以如上面所說一步一步加起來,
不過寫起來稍微麻煩一點點,這邊就讓我偷懶一下吧XD
在Java的部分,設定條件是:
當被要求大多數的字串處理函式都禁止使用時,
該怎麼一步一步寫出我們所要的東西。
首先要建TrieNode,除了上面所述外,我們需要三個函式:
1. insert
透過每個字母沿links的路徑走,
如果curr.links[index] == null 則表示前面還沒走過,
要自行new出來,並設定其word變數。
在走到底的時候我們要將cnt數加1 。
(代表這個word出現在段落裡次數加1次)
行走的路徑如之前提過的,直接使用字元來減去’a’ 即可,
這邊將links[0]視為是’a’,而links[25]視為是’z’ 。
當走到某一條links[index]還沒初始化時,
就將其初始化並給定其word值。
每次往下走時不要忘記將用來迭代到下一個字元的curr指到下一個位置 。
2. ban
只要將該string對應的TrieNode中的cnt設成零 即可。
如果在走的路徑途中遇到null,表示段落裡不存在這個string,
直接return即可。
3. findMax
遍歷所有TrieNode並找到最大的cnt及對應的word。
(這邊使用到res作為結果 的字串及maxcnt作為儲存當前最大值的變數 )
只需要從root的位置開始,往下搜尋有cnt的值,
一一比較即可,當這層搜尋完時,
我們還要往下一層去,所以用迴圈往下再進行遞迴。
(這部分是DFS )
回到mostCommonWord 函式中,
我們先產生一個StringBuilder(命名為st) 及一個root(TrieNode) ,
並用isString 來表示現在st是否構成一個word。
每次將paragraph中的字元取出來,檢查其是否是大小寫字母,
並將字母統一成小寫後接到st上;
一旦發現遇到非大小寫字母的字元,且設定的isString為真 ,
則表示現在st構成一個word,將其丟進root中插入到字典樹內。
(不要忘記最後面還要再檢查一次 ,
因為有可能還沒插入就離開迴圈了)
接著再ban 及findMax 後,就可以回傳res 作為答案了!
Java
Python的部分思路跟Java相近,
不過因直譯器的特性,這邊選擇將對應的函式拉到class Solution來做。
讀者可以兩邊互相對照看看差異。
此外,由於banned測資似乎存在會重複的狀況,
所以可以使用set來縮小總長。
另這邊也提供leetcode上lee215的解:
使用re.findall ,用正規表示式直接將words找出,
再利用Counter直接計算頻率,最終取出最高頻率的字。
(應該是目前最快的解法)
Python
面試實際可能會遇到的問題
「時間/空間複雜度?」
可以從不同面向來考慮。由於有點長,且不好解釋,
這邊直接貼筆者在leetcode上回答的內容。
「這個解法有沒有再更優化的方法?」
(至少有兩個,如果讀者有興趣的話可以嘗試看看:
- 將word的部分去除(也就是只使用中間的鏈結來取得整個字)
- 其實可以先做ban再作insert (ban可將cnt設為**-1** ,而insert時先檢查cnt是否為-1,是的話可以直接跳過)
(這個方法可以同步在insert時更新res和maxcnt,所以會變成先ban再insert完以後,就可以直接回傳答案了,速度應該會再快一點點。))
「Java如果允許使用split呢?」
(可以這樣用:
String[] words = paragraph.toLowerCase().split(“[ !?’,;.]+”); 當然,前提是你不要中間的標點符號漏打XD)
相似及延伸
Special Thanks suggestions/corrections from viewers:
(歡迎提供意見協助更正歐~)
從LeetCode學演算法,我們下次見囉,掰~